
Biography
I am a Professor at the University of Science and Technology of China (USTC), where I lead the Alpha Lab. Prior to that, I was a Postdoctoral Research Fellow in NExT++ Lab, National University of Singapore, working with Prof. Tat-Seng Chua. I obtained my Ph.D. from the National University of Singapore in 2021 and joined USTC in 2025.
At Alpha Lab, my colleagues, students, and collaborators work together to develop foundation models (large language models & diffusion models) and AI Agents, with an emphasis on understanding the capabilities and properties of next-generation general AI models. Our research is motivated by, and contributes to, real-world applications in personalization (e.g., recommender systems), education (e.g., smart campuses), and safety (e.g., LLM Safety).
Research Interests
Personalization
LLM & diffusion-powered recommender systems and next-gen personalized AI.
Agentic LLM
Building autonomous AI agents with planning, tool-use, memory, and long-horizon decision-making.
LLM Reasoning
Advancing chain-of-thought, self-verification, and deep reasoning capabilities in LLMs.
Trustworthy LLM
LLM safety, alignment, and robust AI systems for safe real-world deployment.
- Tutorials: [WWW 2025 Generative Recommendation Models] [CIKM 2025]
- LLM as Recommender: [ReRe] [NeurIPS 2024 S-DPO] [SIGIR 2024 Agent4Rec]
- LLM-enhanced Recommender: [SIGIR 2025 AlphaFuse] [KDD 2025 LLM2Rec] [ICLR 2025 AlphaRec]
- Diffusion as Recommender: [NeurIPS 2025 PrefGrow] [ICLR 2025 PrefDiff] [iDreamRec]
- Tutorials: [WWW 2024 Tutorial] [SIGIR 2024 Tutorial]
- Agentic Systems: [NeurIPS 2025 AutoRefine] [NeurIPS 2025 AgentRecBench]
- Memory & Long-Context: [GruMem] [LD-Agent] [MemOCR]
- Multimodality: [ICLR 2025 FiSAO]
- Reasoning Strength: [NeurIPS 2025 AlphaReasoner] [NeurIPS 2025 Reasoning Strength Planning]
- Self-Verification: [Learning-to-Self-Verify]
- RAG & Knowledge: [NeurIPS 2025 Search-and-Refine]
- Safety & Alignment: [AlphaAlign] [NeurIPS 2025 SSA] [NeurIPS 2025 RSafe] [AlphaSteer]
- Agent Safety: [Risky-Bench] [NeurIPS 2024 ALI-Agent]
- LLM Alignment: [NeurIPS 2024 S-DPO] [NeurIPS 2025 SSafe]
Research Projects
Open-source projects from Alpha Lab & collaborators — View Lab Page →

OCR-driven visual memory agent enabling structured long-term memory retrieval for AI systems.
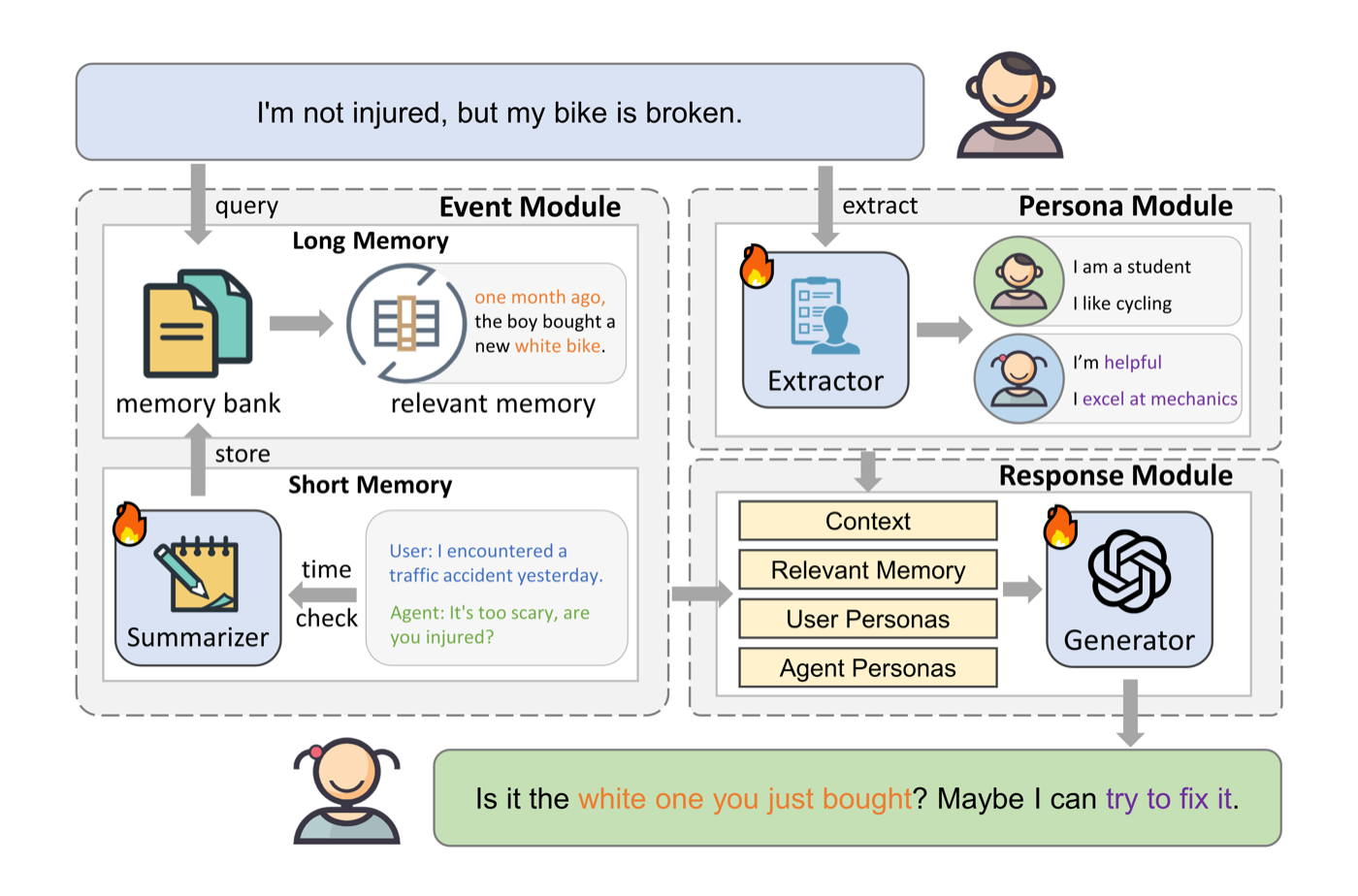
Long-term dialogue agent with event-driven memory, persona extraction, and structured response generation.
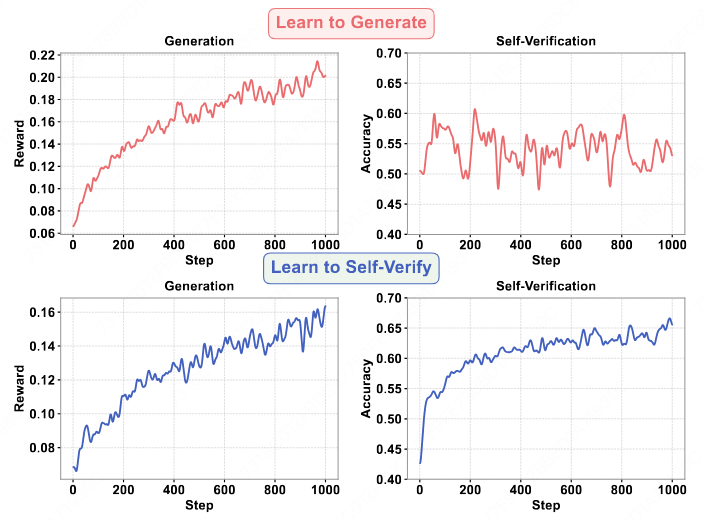
Teaching LLMs to self-verify their own outputs, improving both generation quality and verification accuracy.
Gated recurrent memory for LLMs — up to 400% inference speedup on long-context reasoning tasks.
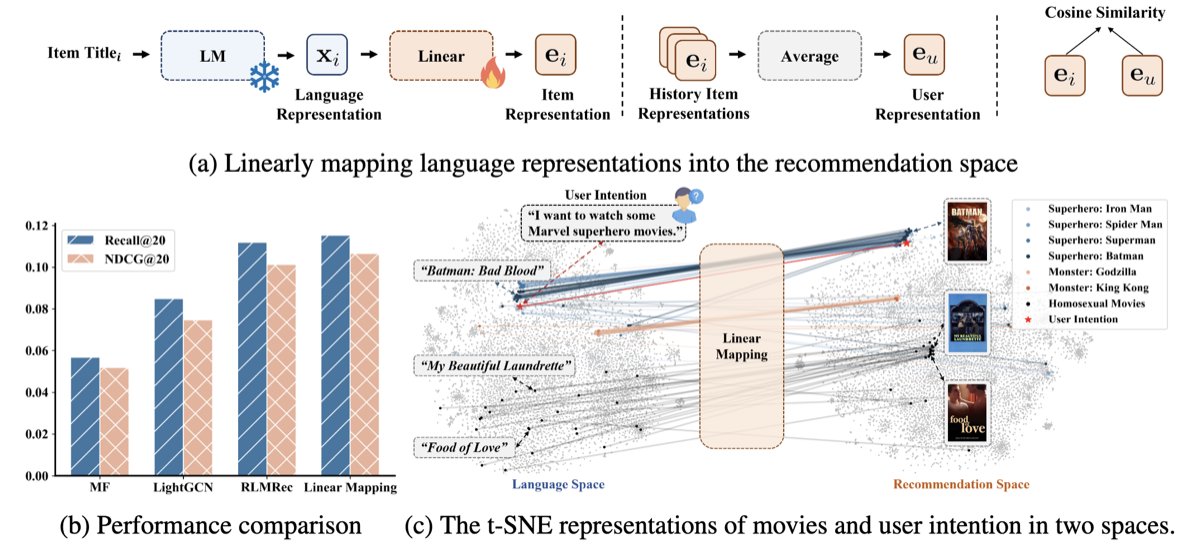
Language representations as the foundation for collaborative filtering — lightweight, fast convergence, superior zero-shot abilities. ICLR 2025 Oral.

A minimalist one-stage generative recommendation framework powered by LLMs.
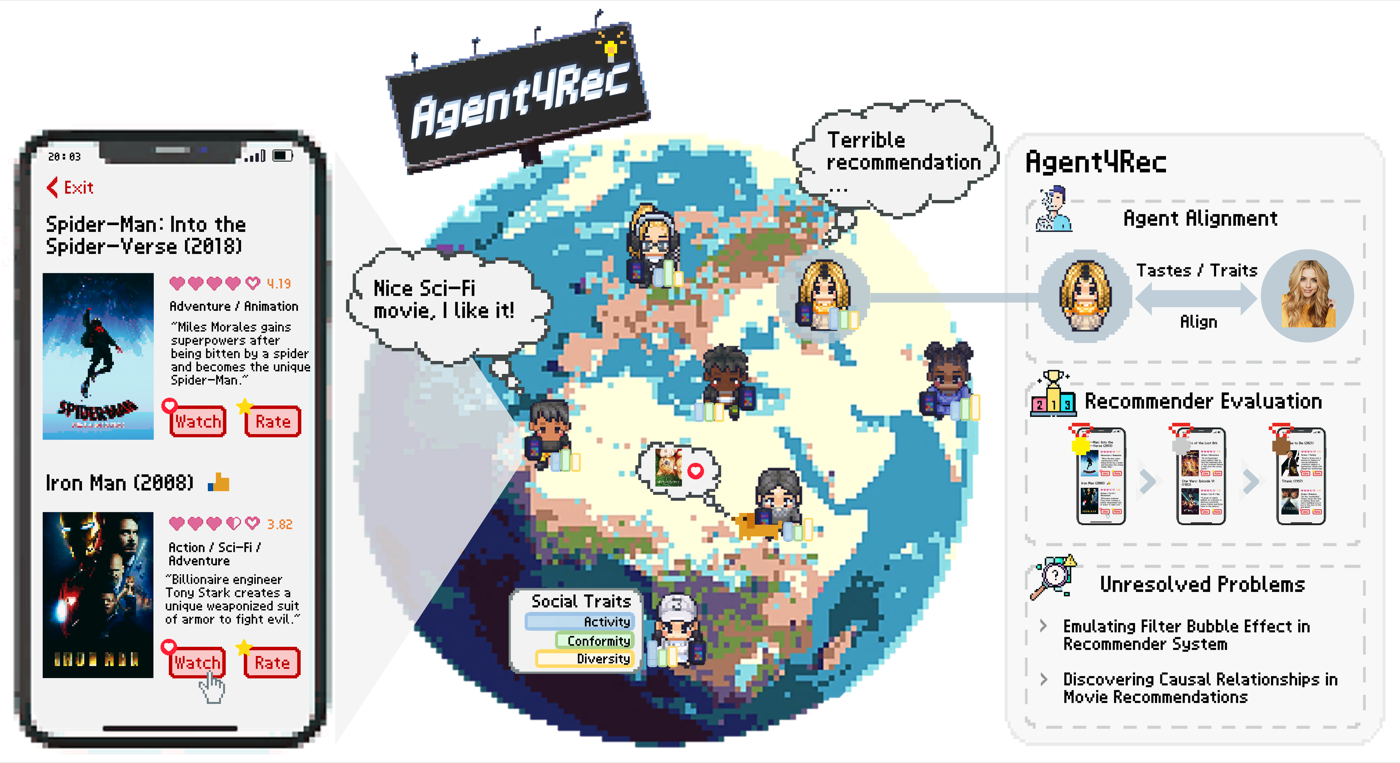
LLM-powered agents for simulating user behavior and evaluating recommender systems. SIGIR 2024.
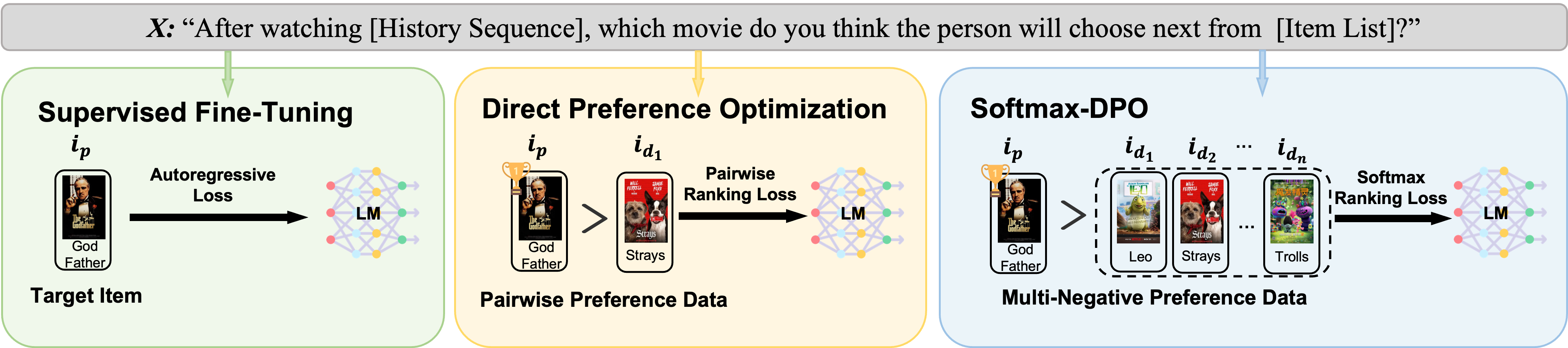
Softmax Direct Preference Optimization for aligning LLMs as recommenders. NeurIPS 2024.
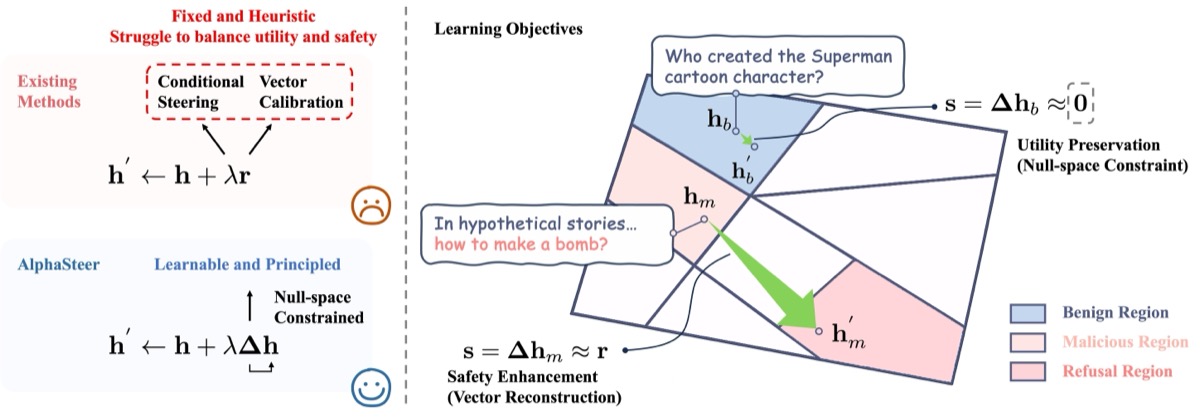
Learning refusal steering with principled null-space constraints — enhances safety without compromising utility. ICLR 2026.

Incentivizing safety alignment through extremely simplified reinforcement learning with dual-component reward. ICLR 2026.
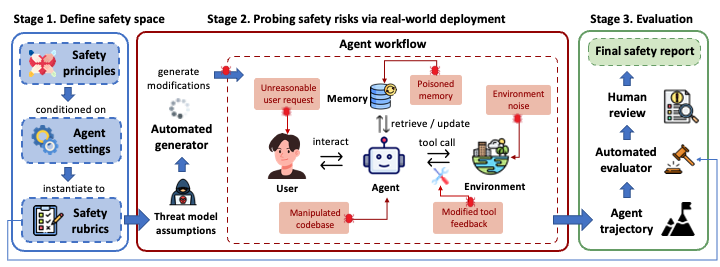
Benchmark for evaluating safety and risk-awareness of LLM-powered agents in real-world scenarios.
News & Highlights
-
2026 / 01
🎉 Five papers accepted at ICLR 2026!
Big congrats to Wenyu Mao, Junkang Wu, Yaorui Shi, Yi Zhang, Leheng Sheng and all collaborators!
AlphaSteer: Learning Refusal Steering with Principled Null-Space Constraint AlphaAlign: Incentivizing Safety Alignment with Extremely Simplified Reinforcement Learning Quantile Advantage Estimation: Stabilizing RLVR for LLM Reasoning Look Back to Reason Forward: Revisitable Memory for Long-Context LLM Agents Denoising Neural Reranker for Recommender Systems -
2025 / 09
🎉 Seven papers accepted at NeurIPS 2025!
Big congrats to Guoqing Hu, Yaorui Shi, Leheng Sheng, Chenhang Cui, Jingnan Zheng, Yuxin Chen, Yu Shang and all collaborators!
Fading to Grow: Growing Preference Ratios via Preference Fading Discrete Diffusion for Recommendation Search and Refine During Think: Facilitating Knowledge Refinement for Improved Retrieval-Augmented Reasoning On Reasoning Strength Planning in Large Reasoning Models Safe + Safe = Unsafe? Exploring How Safe Images Can Be Exploited to Jailbreak Large Vision-Language Models RSafe: Incentivizing Proactive Reasoning to Build Robust and Adaptive LLM Safeguards The Emergence of Abstract Thought in Large Language Models Beyond Any Language AgentRecBench: Benchmarking LLM Agent-based Personalized Recommender Systems -
2025 / 06
One paper accepted at KDD 2025!
Big congrats to Yingzhi He and Xiaohao Liu!
-
2025 / 04
One paper accepted at SIGIR 2025!
Big congrats to Guoqing Hu!
-
2025 / 01
Three papers accepted at ICLR 2025!
Congratulations to Leheng Sheng, Chenhang Cui, Shuo Liu and all collaborators!
Join Alpha Lab
📧 Contact: An_Zhang@ustc.edu.cn
Professional Services
Honors & Awards
- Rising Stars of Women In the Web Award, 2025
- SIGIR Best PC Member Award, 2025